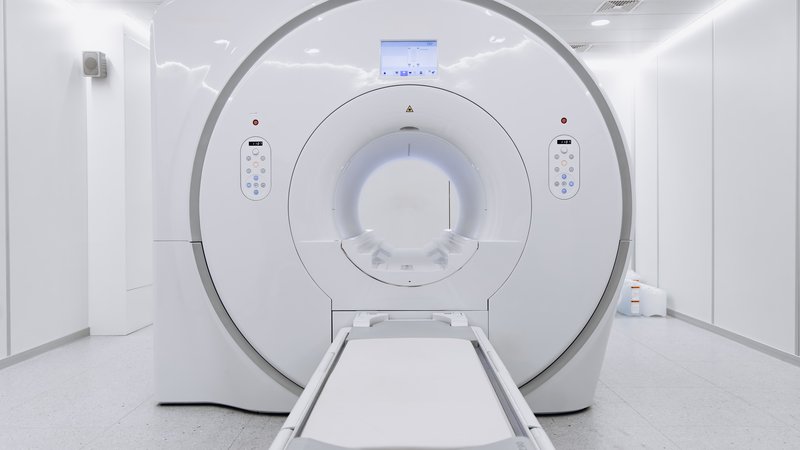
醫療影像 AI 正在悄悄撞上一個值得打造者注意的轉折點。常規高場 MRI 機器造價 100 萬到 300 萬美元,需要液氦,需要有重型屏蔽的專用機房,一個地區往往只在少數幾家醫院裡。低場 MRI 機器(場強大約在 0.05 到 0.5 Tesla,而不是 1.5 到 3 Tesla)只要前者的一小部分錢,能在普通電源插座上跑,不需要氦,也能放進較小的設施裡。一直以來的代價是影像品質:訊號更弱、雜訊更多、解析度更低。AI 現在正在把這條差距壓下去。已經發表的臨床研究報告,在特定成像任務上、約 100 名受試者的世代研究中,AI 強化的低場 MRI 的結果已經能和常規機器平起平坐。文獻中一台 0.05T 的參考機器耗電約 1800 瓦,和一把吹風機差不多。
AI 這一層在做三件事。第一,用低場-高場配對掃描訓練出來的超解析重建,讓模型把雜訊大的低場資料向上取樣到接近高階硬體輸出的品質。第二,去噪擴散與基於 Transformer 的方法,在不引入早期 GAN 類方法那種「幻覺出來的解剖結構」的前提下,處理較低的訊噪比。第三,針對特定解剖部位(腦、肺、肌骨)訓練的重建模型,透過解剖先驗來彌補低場物理在對比度上的損失。大廠把這類能力以不同商標推出:西門子的 Deep Resolve、GE 的 Effortless Imaging AI、Hyperfine 的可攜式 Swoop 系統。獨立學術界的工作也在開放資料集上重現了核心結果。要注意的是:AI 重建出來的影像,對研究充分的常見解剖結構與常見病理是可診斷可用的;罕見發現、非典型表現、在訓練資料裡嚴重代表不足的解剖部位,就是重建最容易掉鏈子的地方,而圍繞這一塊的監管圖景還在成形。
這是一個值得被命名的模式,因為它一直在反覆出現。智慧型手機相機把傻瓜機打下去,不是因為小感光元件在物理上追上了大感光元件,而是因為計算攝影(多幀融合、深度去噪、用於人像模式的語義切分)跨過了物理品質的鴻溝。降噪耳機在音訊上走的也是同一條路。現在 AI 重建在醫療影像上重演了一遍。能夠一般化的那句話是:當一項物理量測偏雜訊、低解析或昂貴時,一張以高品質配對參考訓練出來的神經網路,經常能在硬體成本的很小一部分上把差距補上。這在訊號自身結構足夠、讓模型能「猜」出昂貴版本會產生什麼的情境下成立,而大多數生物與物理世界訊號都屬於這一類。它不成立的情境,是便宜感測器收到的訊號在資訊意義上就是真的太稀了,沒有先驗能把從來沒被收到過的資料「生」出來。對打造者來說,一條有用的準則是:永遠先問問自己,你為硬體多付的這部分成本,是在為物理買單,還是在為便利買單;後一種往往是可以替換掉的。
如果你在做醫療影像產品,實際的問題是:你這一套具體的「低場 + AI」堆疊會走哪一條監管路徑。FDA 已經核准了多家廠商的系統,但合規的負擔是按模型、按適應症一項一項走的,所以大多數情況下,基於已經過審的重建 API 做原型,比你自己另起爐灶更快。如果你在做更廣義的硬體相鄰 AI,有三條具體的經驗法則。第一,去找那些高階硬體比預算硬體貴 10 倍到 100 倍的領域,然後問:被以不同方式量測的究竟是哪一種物理量?如果差距主要在訊噪比,而不在根本靈敏度,那 AI 重建大機率可行。第二,配對資料才是護城河,不是模型;誰手上有這個領域裡大規模的「便宜-高階」配對量測資料,誰就先把重建做出來。第三,你在上面做原型的硬體平台,遠遠沒有「你能拿到什麼訓練資料」重要;一個便宜但 API 友善的感測器,總是勝過一個更強但資料通路被鎖住的感測器。醫療影像是這波遷移中目前最顯眼的一個案例。類似的動力學正在開始在顯微成像、衛星影像、工業檢測裡起作用,打造者的這一套思路是可以遷移過去的。